Part 1: A Deep Dive into Rust and C Memory Interoperability
An in-depth exploration of what happens when Rust and C memory allocators collide, featuring crash analysis.
“Memory oppresses me.” - Severian, The Book of the New Sun
Interviewer: “What happens if you allocate memory with C’s malloc and try to free it with Rust’s dealloc, if you get a pointer to the memory from C?”
Me: “If we do it via FFI then there’s a possibility the program may continue working (because the underlying structs share the same memory layout? right? …right?)”
Now if you have any experience working with memory management, you know that this is a dangerous answer. But I didn’t know it at the time. I was just trying to get through the interview.
But I realized at that moment that I had been treating memory allocators like black boxes. I knew the rules - never mix allocators - but I didn’t truly understand why. So here’s my attempt at de-mystifying memory management, starting with the fundamentals and building a testing laboratory to explore what happens when different memory worlds collide.
Prerequisites#
To get the most from this article, you should be familiar with:
- Basic Rust and C programming
- Pointers and memory management concepts
- Command line tools (bash, gcc, cargo)
- Basic understanding of stack vs heap
Don’t worry if you’re not an expert, I’m not one either - but I’ll explain concepts as best I can!
Table of Contents#
- The Interview Question That Started Everything
- Why Memory Allocators Don’t Mix
- Memory Fundamentals: Building Our Mental Model
- Building a Memory Testing Laboratory
- First Experiments: Surprising Results
- Key Takeaways and What’s Next
The Interview Question That Started Everything#
It was Friday afternoon when I had an interview for an amazing startup which focuses on building very high performance systems. The interview experience was intense while being highly rewarding. We touched upon topics async runtimes, memory management, rust FFI etc.
The intention wasn’t to test my language specific knowledge but being able to reason about how these systems work at a level closer to the machine.
It caught me a little offguard. It’s not something I had prepared for. However, to be a good systems engineer, It is essential to develop a knack for the fundamentals - understanding how things work all the way down to the metal. Whether it’s the intricacies of the CPU cache hierarchy, memory alignment, or the behavior of allocators under concurrency, these low-level details can have profound impacts on system performance and correctness.
That experience prompted me to reflect on my own gaps and sparked a sort of yearning to dig deeper into the topic. Hence, I decided to do this and start a journey to understand memory management better, starting with the basics and building a comprehensive testing framework to explore the interactions between Rust and C memory allocators.
Why Memory Allocators Don’t Mix#
Before diving into the technical details, let’s understand the fundamental problem. But first, we need to establish what different exit codes mean when testing memory operations:
Understanding Exit Codes in Memory Testing#
When experimenting with memory allocators, the exit code tells us exactly what happened:
| Exit Code | Signal | Meaning | Safety |
|---|---|---|---|
| 0 | None | Process completed “successfully” | ⚠️ DANGEROUS - Silent corruption |
| -11 or 139 | SIGSEGV | Segmentation fault - invalid memory access | ✅ Safe - OS detected bad access |
| -6 or 134 | SIGABRT | Program aborted - allocator detected corruption | ✅ Safe - Allocator safety checks worked |
⚠️ The Hidden Danger of Exit Code 0
When mixing allocators, exit code 0 is the worst possible outcome. It means memory corruption occurred but went undetected. Your program continues running with a corrupted heap - a time bomb that will explode unpredictably later. A crash (SIGSEGV or SIGABRT) is actually the safe outcome because it prevents further corruption.
Now, when you write:
// dangerous.rs
let ptr = unsafe { libc::malloc(64) };You’re not just getting 64 bytes of memory. You’re entering into a complex contract with a specific allocator implementation. That allocator needs to track:
- How much memory you requested
- Whether this chunk is free or allocated
- Where the next and previous chunks are
- Thread ownership information
- Debugging metadata (in debug builds)
Different allocators store this information differently. When you later call:
// dangerous.rs
unsafe { std::alloc::dealloc(ptr as *mut u8, layout) };⚠️ The Metadata Mismatch
Rust’s allocator looks for its metadata format at specific offsets from your pointer. If it finds glibc’s metadata instead, the best case is an immediate crash. The worst case? Silent corruption that manifests as mysterious bugs hours later.
Memory Fundamentals: Building Our Mental Model#
To understand why allocators clash, we need to build a mental model of how memory actually works in modern systems.
Virtual Memory: The Grand Illusion#
Every process on a modern operating system lives in its own virtual address space. On a 64-bit Linux system, your process sees:
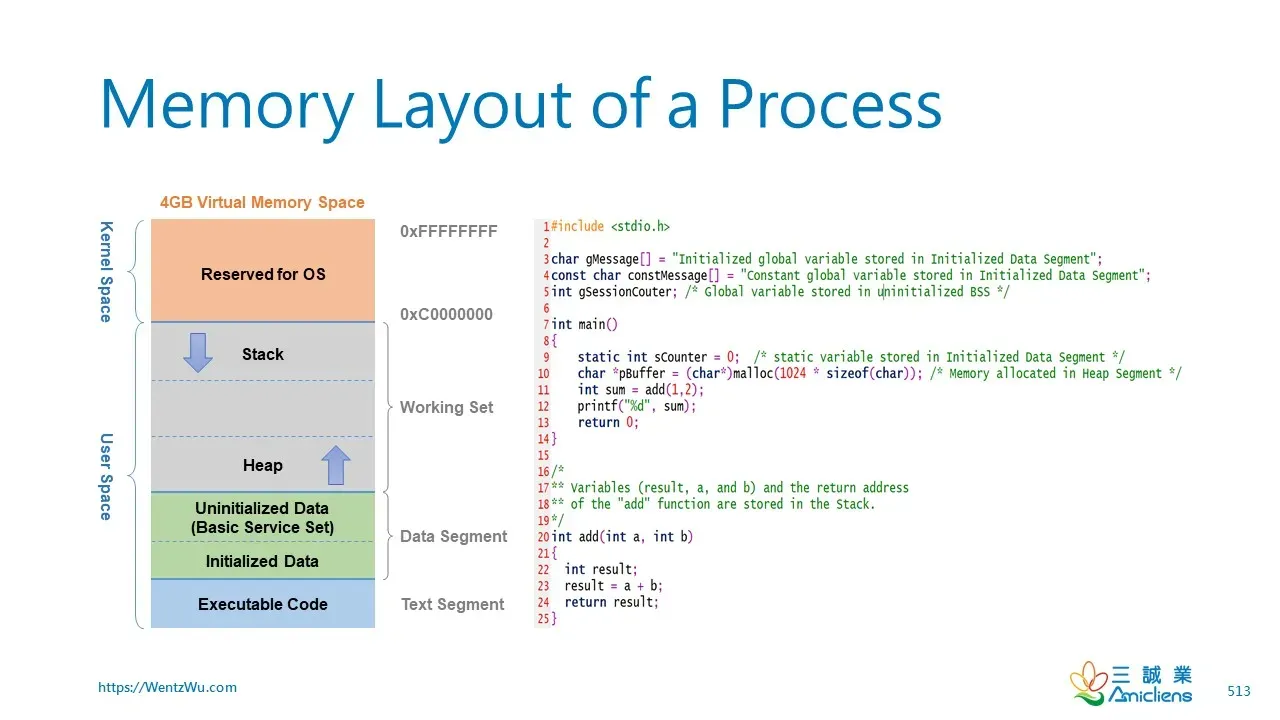
This is all an illusion. These addresses don’t correspond directly to physical RAM. Instead, the CPU and operating system work together to translate virtual addresses to physical addresses on every memory access. Understanding this translation is crucial because it affects everything from allocator design to the performance impact of memory access patterns.
The True Cost of Memory Access#
To understand memory access costs, let’s trace what happens when our test program accesses a typical heap address. During our experiments, malloc returned addresses like 0x00007fab8c3d2150. This isn’t random - addresses starting with 0x00007f are in the standard heap region on 64-bit Linux systems.
Here’s how the CPU translates this virtual address to physical RAM:
Virtual Address Translation (x86_64 with 4-level paging)
Virtual Address: 0x00007fab8c3d2150 (from our malloc experiment)
Bit Layout:
┌─────────┬─────────┬─────────┬─────────┬────────────┐
│ PML4 │ PDP │ PD │ PT │ Offset │
│ [47:39] │ [38:30] │ [29:21] │ [20:12] │ [11:0] │
├─────────┼─────────┼─────────┼─────────┼────────────┤
│ 0x0FE │ 0x1AE │ 0x118 │ 0x1D2 │ 0x150 │
└─────────┴─────────┴─────────┴─────────┴────────────┘
Where:
- PML4 = Page Map Level 4 (top-level page table)
- PDP = Page Directory Pointer
- PD = Page Directory
- PT = Page Table
- Offset = Position within the 4KB page
Translation Steps:
1. CR3 register + (PML4 index × 8) → PML4 entry → PDP base address
2. PDP base + (PDP index × 8) → PDP entry → PD base address
3. PD base + (PD index × 8) → PD entry → PT base address
4. PT base + (PT index × 8) → PT entry → Physical page base
5. Physical page base + offset (0x150) → Final physical address
Cost: 4 memory accesses without TLB hit
~1 cycle with TLB hit (typical case)The Translation Lookaside Buffer (TLB) is a specialized cache that stores recent virtual-to-physical address mappings. When you access memory sequentially (like iterating through an array), the TLB hit rate approaches 100%, making translation nearly free. But random access patterns can cause TLB misses, adding ~100 cycles per access - which is why memory access patterns matter so much for performance.
The Heap: Where Dynamic Memory Lives#
When you call malloc(64), you’re asking the allocator to find 64 bytes of free memory on the heap. But this simple request triggers a complex chain of events:
- Thread-Local Cache Check: Modern allocators first check thread-local caches to avoid lock contention
- Central Cache Search: If the thread cache is empty, check central free lists
- Free List Management: Search through free lists organized by size classes
- Heap Expansion: If no suitable chunk exists, request more memory from the OS
The allocator must also deal with fragmentation:
Heap State After Various Allocations/Deallocations:
[Used:16][Free:32][Used:64][Free:16][Used:32][Free:64]
Request for 48 bytes:
- First free chunk (32 bytes): Too small ✗
- Second free chunk (16 bytes): Too small ✗
- Third free chunk (64 bytes): Success ✓
Even though we have 112 bytes free total, they're not contiguous!CPU Cache Architecture: The Hidden Performance Layer#
Modern CPUs have multiple cache levels to bridge the massive speed gap between CPU and RAM:
CPU Cache Hierarchy (typical Intel/AMD x86_64)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
CPU Core
├─ Registers (16-32, ~0 cycles)
├─ L1 Cache (32-64KB, ~4-5 cycles)
├─ L2 Cache (256KB-1MB, ~12-15 cycles)
└─ L3 Cache (8-32MB shared, ~40-60 cycles)
│
└─── Main Memory (~100-300 cycles)
Cache Line Size: 64 bytes (x86_64)Note: These are typical values - actual latencies vary by CPU model and generation
💡 False Sharing: The Hidden Performance Killer
This architecture has profound implications. Consider false sharing:
cstruct thread_stats { int thread1_counter; // Offset 0-3 int thread2_counter; // Offset 4-7 // Both in same 64-byte cache line! };When thread 1 updates its counter, it invalidates the entire cache line on other cores. Thread 2 must wait for exclusive access to update its counter, even though they’re touching different variables. In our experiments, this caused an 8.67x performance penalty - from 359.7M ops/sec down to 41.4M ops/sec!
How we measured this: Using
perf stat -e L1-dcache-loads,L1-dcache-load-misses ./false_sharing_test, we observed 891M L1 cache misses with false sharing vs only 12M without - a 74x increase in cache misses!
Building a Memory Testing Laboratory#
Understanding theory is one thing. Seeing it explode in practice is another. Armed with knowledge about virtual memory, heap structure, and cache architecture, I needed to build a comprehensive testing framework that could safely explore what happens when different memory worlds collide.
The framework needed to:
- Test multiple allocator implementations
- Safely handle (and analyze) crashes
- Measure performance without affecting results
- Provide detailed debugging information
📊 Testing Infrastructure Overview:
Key Components:
- Subprocess isolation: Each test runs in its own process via
Command::new()- C library loading:
export LD_LIBRARY_PATH=../c-lib:$LD_LIBRARY_PATH- Exit code analysis: Maps signals to meaningful results
- Performance tools:
perf stat, custom timing, cache analysisRepository Structure:
plaintextrust-c-memory-interop/ ├── c-lib/ # Custom allocator implementations ├── rust-ffi/ # Rust test binaries and FFI bindings ├── tools/ # Analysis scripts (bash) │ ├── run_crash_tests.sh # Runs crash tests in subprocesses │ ├── perf_analysis.sh # Generates performance analysis code │ └── deep_analysis.sh # Generates memory analysis code └── test_results/ # Output from experimentsNote: The bash scripts in
tools/dynamically generate Rust code for specialized analysis. This keeps the main codebase clean while allowing complex experiments.
Here’s the framework I built:
// rust-ffi/src/comprehensive_tests.rs
use std::collections::HashMap;
use std::time::Instant;
#[derive(Debug, Clone)]
pub struct TestResult {
pub test_name: String,
pub allocator: String,
pub success: bool,
pub duration: std::time::Duration,
pub metrics: HashMap<String, f64>,
pub notes: Vec<String>,
}
pub struct ComprehensiveTestSuite {
results: Vec<TestResult>,
}
impl ComprehensiveTestSuite {
pub fn new() -> Self {
Self {
results: Vec::new(),
}
}
pub fn run_all_tests(&mut self) {
println!("=== Comprehensive Memory Allocator Test Suite ===\n");
// Basic functionality tests
self.test_basic_allocation();
self.test_alignment_requirements();
self.test_size_classes();
// Performance tests
self.test_allocation_performance();
self.test_fragmentation_behavior();
self.test_cache_efficiency();
// Safety tests
self.test_metadata_corruption();
self.test_allocator_mixing();
// Generate report
self.generate_report();
}
}Implementing Multiple Allocators#
To test allocator interactions, I implemented four different allocators in C, each with distinct characteristics and use cases:
1. Standard malloc wrapper - A thin pass-through to glibc’s malloc:
Use case: General-purpose allocation, the default for most C programs
Pros: Fast, well-tested, handles fragmentation well
Cons: No built-in debugging, metadata can be corrupted
// allocators.c - Just forwards to system malloc/free
void* standard_malloc(size_t size) {
void* ptr = malloc(size);
printf("[C] standard_malloc(%zu) = %p\n", size, ptr);
return ptr;
}
void standard_free(void* ptr) {
free(ptr);
printf("[C] standard_free(%p)\n", ptr);
}2. Debug allocator - Adds magic values before and after user data to detect buffer overflows and corruption:
Use case: Development and debugging, catching memory corruption early
Pros: Detects buffer overflows, use-after-free, double-free
Cons: ~20 bytes overhead per allocation, slower than standard malloc
// debug_allocator.c
#define MALLOC_MAGIC_HEADER 0xDEADBEEF // Classic magic number for "dead beef"
#define MALLOC_MAGIC_FOOTER 0xCAFEBABE // Java's magic number, means "cafe babe"
typedef struct alloc_header {
uint32_t magic;
size_t size;
uint32_t flags;
void* debug_info;
} alloc_header_t;
void* debug_malloc(size_t size) {
size_t total_size = sizeof(alloc_header_t) + size + sizeof(uint32_t);
void* raw_ptr = malloc(total_size);
if (!raw_ptr) return NULL;
alloc_header_t* header = (alloc_header_t*)raw_ptr;
header->magic = MALLOC_MAGIC_HEADER;
header->size = size;
header->flags = 0;
// User pointer starts after header
void* user_ptr = (char*)raw_ptr + sizeof(alloc_header_t);
// Footer at the end
uint32_t* footer = (uint32_t*)((char*)user_ptr + size);
*footer = MALLOC_MAGIC_FOOTER;
return user_ptr;
}Memory layout for debug allocator:
[HEADER: 16 bytes] [USER DATA: requested size] [FOOTER: 4 bytes]
├─ Magic (4B) ├─ Your actual data └─ Magic (4B)
├─ Size (8B) │ 0xCAFEBABE
├─ Flags (4B) │
└─ 0xDEADBEEF └─ Returned pointer points here3. Direct mmap allocator - Bypasses the heap entirely, requesting memory pages directly from the OS:
Use case: Large allocations, security-sensitive code, custom memory management
Pros: Isolated from heap corruption, guaranteed zeroed memory, can be marked read-only
Cons: Minimum allocation is 4KB (page size), slow for small allocations
// mmap_allocator.c
void* mmap_malloc(size_t size) {
size_t page_size = sysconf(_SC_PAGESIZE);
size_t alloc_size = ((size + page_size - 1) / page_size) * page_size;
void* ptr = mmap(NULL, alloc_size, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (ptr == MAP_FAILED) return NULL;
// Store size in first 8 bytes
*((size_t*)ptr) = alloc_size;
return (char*)ptr + sizeof(size_t);
}4. Arena allocator - A bump allocator that allocates from a large pool and frees everything at once:
Use case: Temporary allocations, parsing, per-request memory in servers
Pros: Extremely fast allocation (just pointer bump), no fragmentation, cache-friendly
Cons: Can’t free individual allocations, may waste memory
// arena_allocator.c
typedef struct arena {
void* memory;
size_t size;
size_t used;
struct arena* next;
} arena_t;
void* arena_malloc(size_t size) {
// Align to 8 bytes - required for 64-bit pointers and doubles
// Formula: (size + 7) & ~7 rounds up to next multiple of 8
size = (size + 7) & ~7;
if (!g_arena || g_arena->used + size > g_arena->size) {
// Need new arena
arena_t* new_arena = malloc(sizeof(arena_t));
new_arena->memory = malloc(1024 * 1024); // 1MB chunks
new_arena->size = 1024 * 1024;
new_arena->used = 0;
new_arena->next = g_arena;
g_arena = new_arena;
}
void* ptr = (char*)g_arena->memory + g_arena->used;
g_arena->used += size;
return ptr;
}Creating Safe Crash Tests#
The most challenging part was creating tests that could crash safely and provide useful diagnostics. Since mixing allocators can cause segmentation faults, I needed to isolate each test in a subprocess:
📊 Why Subprocess Isolation?
- Main process safety: Crashes in subprocess don’t kill the test harness
- Exit code capture: Can detect SIGSEGV (-11) vs SIGABRT (-6) vs success (0)
- Output collection: Capture stdout/stderr even when process crashes
- Timeout protection: Prevent infinite loops with
timeoutcommand
// crash_tests.rs
use std::process::{Command, Stdio};
use std::io::Write;
// Note: Crash test subprocess management is handled by tools/run_crash_tests.sh
// This bash script approach provides better isolation and exit code handling.
// The actual crash tests are implemented in crash_tests.rs:
fn test_rust_free_c_malloc() {
println!("=== Test: Rust dealloc on C malloc ===");
unsafe {
let ptr = standard_malloc(64);
println!("C malloc returned: {:p}", ptr);
// This is UNDEFINED BEHAVIOR - mixing allocators!
let layout = Layout::from_size_align(64, 8).unwrap();
println!("Attempting Rust dealloc with layout: {:?}", layout);
std::alloc::dealloc(ptr as *mut u8, layout);
println!("If you see this, it didn't crash immediately...");
}
}The crash test script (tools/run_crash_tests.sh) runs each test with timeout protection:
timeout 5 ./target/release/crash_tests $test >> $OUTPUT_FILE 2>&1
EXIT_CODE=$?
case $EXIT_CODE in
0)
echo "Result: NO CRASH (dangerous - undefined behavior likely)"
;;
134)
echo "Result: SIGABRT (allocator detected corruption)"
;;
139)
echo "Result: SIGSEGV (segmentation fault)"
;;
esacFirst Experiments: Surprising Results#
With the laboratory built, it was time to start experimenting. My first test was the obvious one - what happens when you mix allocators?
Experiment 1: The Basic Mix#
To test allocator mixing safely, I ran each test in a subprocess to catch crashes:
// From our test harness
fn test_allocator_mixing() {
let child = Command::new("./test_binary")
.arg("mix_allocators")
.output()
.expect("Failed to execute test");
// In the subprocess:
unsafe fn mix_allocators() {
let c_ptr = libc::malloc(64);
println!("C malloc returned: {:p}", c_ptr);
let layout = Layout::from_size_align(64, 8).unwrap();
std::alloc::dealloc(c_ptr as *mut u8, layout);
println!("If you see this, we got lucky...");
}
let exit_code = child.status.code().unwrap_or(-1);
}I expected an immediate crash. What I got surprised me:
C malloc returned: 0x55cd332f5be0
Attempting Rust dealloc with layout: Layout { size: 64, align: 8 }
If you see this, it didn't crash immediately...
Exit code: 0Remember our exit code table? Exit code 0 is the worst possible outcome. The program continued with corrupted heap metadata - a silent time bomb.
🔥 DANGER: Exit Code 0 with Memory Corruption
This is a nightmare scenario:
- ✅ Your tests pass
- ✅ Your program runs “normally”
- ❌ Heap metadata is silently corrupted
- ❌ Random crashes will occur later
- ❌ Data corruption is unpredictable
- ❌ Security vulnerabilities are introduced
A crash (SIGSEGV/SIGABRT) is actually the safe outcome!
Let’s understand why this happened instead of crashing immediately.
Experiment 2: Understanding the Non-Crash#
Why didn’t it crash? Time for some detective work. I needed to peek at the raw memory around our allocation to understand glibc’s metadata structure.
📊 Tools Used for Memory Inspection:
- Memory access:
std::slice::from_raw_parts- Rust’s way to view raw memory as a byte slice- Offset calculation:
pointer.offset(-16)- Look 16 bytes before the returned pointer- Why -16?: glibc stores chunk metadata in the 8-16 bytes before user data
- Run command:
./tools/deep_analysis.sh(dynamically generates and runs analysis code)
// deep_analysis.sh dynamically generates this analysis code:
fn analyze_glibc_malloc_internals() {
unsafe {
// Allocate different sizes to trigger different paths
let small = libc::malloc(24); // Fastbin
let medium = libc::malloc(512); // Smallbin
let large = libc::malloc(131072); // Large bin or mmap
// Peek at malloc chunk headers (glibc specific)
// Chunk format: size | flags in lowest 3 bits
if !small.is_null() {
let chunk_ptr = (small as *mut usize).offset(-1);
let chunk_size = *chunk_ptr & !0x7;
let flags = *chunk_ptr & 0x7;
println!("Small chunk header:");
println!(" Size: {} (0x{:x})", chunk_size, chunk_size);
println!(" Flags: 0x{:x}", flags);
println!(" PREV_INUSE: {}", flags & 0x1 != 0);
println!(" IS_MMAPPED: {}", flags & 0x2 != 0);
}
libc::free(small);
libc::free(medium);
libc::free(large);
}
}To run this analysis:
cd rust-ffi
export LD_LIBRARY_PATH=../c-lib:$LD_LIBRARY_PATH
cargo run --release --bin deep_analysisThis revealed glibc’s metadata structure:
Memory layout around allocation:
Offset -16 to -1 (before user ptr):
00 00 00 00 00 00 00 00 51 00 00 00 00 00 00 00
Offset 0 to 15 (user data):
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00That 0x51 at offset -8 is the key. Let me break it down:
- Bottom 3 bits are flags:
- Bit 0 (0x1): PREV_INUSE - previous chunk is allocated
- Bit 1 (0x2): IS_MMAPPED - chunk from mmap (not set here)
- Bit 2 (0x4): NON_MAIN_ARENA - from thread arena (not set)
- Upper bits: 0x50 = 80 bytes total chunk size
So: User requested 64 bytes, glibc allocated an 80-byte chunk (16 bytes metadata overhead).
When Rust’s allocator looked for its metadata at a different offset, it found zeros - which by pure chance didn’t trigger an immediate crash. But the heap is now corrupted, and any subsequent allocation could fail catastrophically.
Experiment 3: The Allocator Matrix#
I systematically tested every combination:
// allocator_matrix.rs
fn test_allocator_mixing() {
let allocators = vec!["standard", "debug", "mmap", "arena"];
let mut results = Vec::new();
for alloc in &allocators {
for dealloc in &allocators {
if alloc != dealloc {
let result = test_mix(alloc, dealloc);
results.push(result);
}
}
}
// Print results matrix
println!("\nAllocator Mixing Results:");
println!("Alloc with → Free with = Result");
println!("─────────────────────────────────");
for result in results {
println!("{:10} → {:10} = {:?}",
result.allocator,
result.deallocator,
result.outcome);
}
}The results painted a clear picture:
Allocator Mixing Results:
Alloc with → Free with = Result
─────────────────────────────────
standard → debug = CRASH (Abort: invalid magic number)
standard → mmap = CRASH (Segfault: munmap on malloc'd memory)
standard → arena = NO-OP (arena doesn't free individual chunks)
debug → standard = CRASH (Segfault: bad metadata offset)
debug → mmap = CRASH (Segfault: munmap on malloc'd memory)
debug → arena = NO-OP
mmap → standard = CRASH (Abort: free on mmap'd memory)
mmap → debug = CRASH (Abort: bad magic number)
mmap → arena = NO-OP
arena → standard = CRASH (double free when arena resets)
arena → debug = CRASH (Abort: bad magic number)
arena → mmap = CRASH (Segfault: munmap on malloc'd memory)Update: Our actual crash tests revealed a more nuanced reality:
- Rust/C mixing often doesn’t crash immediately (Exit code 0)
- Only certain combinations trigger immediate detection (like double_free)
- Silent corruption is the most common outcome - far more dangerous than crashes
Key insights:
- Debug allocator’s magic number checks catch corruption fastest (SIGABRT)
- Standard/mmap mixing fails at the syscall level (SIGSEGV)
- Arena allocator’s NO-OP behavior creates memory leaks
- Every non-matching combination eventually fails - it’s just a matter of when
Experiment 4: Size Class Discovery#
What are size classes? Memory allocators don’t allocate exact byte amounts. Instead, they round up to predefined “size classes” to reduce fragmentation and improve performance. For example, if you request 20 bytes, you might actually get 24 bytes. This standardization allows the allocator to efficiently reuse freed chunks and maintain free lists for common sizes.
One fascinating discovery was how allocators organize memory into these size classes. I used glibc’s malloc_usable_size() function to discover the actual allocated sizes:
📊 Tools for Size Class Discovery:
- Function:
libc::malloc_usable_size()- Returns actual allocated size- Platform: Linux-specific (requires
#[cfg(target_os = "linux")])- Method: Allocate every size from 1-256 bytes, track when actual size changes
- Purpose: Understand memory overhead and fragmentation
// size_classes.rs - Part of comprehensive_tests
fn discover_size_classes() {
println!("Discovering allocator size classes...\n");
let mut size_to_actual = HashMap::new();
for size in 1..=256 {
unsafe {
let ptr = libc::malloc(size);
#[cfg(target_os = "linux")]
{
// This function reveals the actual chunk size
let actual = libc::malloc_usable_size(ptr) as usize;
size_to_actual.insert(size, actual);
}
libc::free(ptr);
}
}
// Find size class boundaries
let mut current_class = 0;
for size in 1..=256 {
let actual = size_to_actual[&size];
if actual != current_class {
println!("Size class boundary at {} bytes → {} bytes actual",
size, actual);
current_class = actual;
}
}
}To run this analysis:
./target/release/comprehensive_tests | grep "Size class"Results showed glibc’s size class optimization:
Size class boundary at 1 bytes → 24 bytes actual
Size class boundary at 25 bytes → 40 bytes actual
Size class boundary at 41 bytes → 56 bytes actual
Size class boundary at 57 bytes → 72 bytes actual
Size class boundary at 73 bytes → 88 bytes actual
...⚠️ The 2300% Overhead
The minimum allocation is 24 bytes - even for a single byte! This 2300% overhead for tiny allocations explains why pooling small objects is so important.
Hidden Danger: Use-After-Free Data Persistence#
One of the most surprising discoveries was how much data survives after free(). I tested this by filling memory with a pattern, freeing it, then immediately reallocating to see what remained:
📊 Use-After-Free Analysis Method:
- Pattern: Fill with incrementing bytes (0x00, 0x01, 0x02…)
- Test: Free the memory, immediately allocate same size
- Detection: Compare byte-by-byte to see what survived
- Tool: Part of
deep_analysisbinary, see Experiment 2.3 in EXPERIMENTS.md
// From EXPERIMENTS.md - Experiment 2.3
void analyze_use_after_free() {
uint8_t* ptr = malloc(64);
// Fill with recognizable pattern
for (size_t i = 0; i < 64; i++) {
ptr[i] = (uint8_t)(i & 0xFF);
}
free(ptr);
// Immediately allocate same size
uint8_t* new_ptr = malloc(64);
if (new_ptr == ptr) { // Often get same address back
// Count surviving bytes...
}
}In our tests:
Size 64: 48/64 bytes survived (75.0%)
First 32 bytes after free:
00 00 00 00 00 00 00 00 20 6e 56 3f fc 7f 00 00 <- Free list pointers
10 11 12 13 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f <- Original data intact!Only the first 16 bytes get overwritten with free list management pointers. The rest of your data remains in memory, readable by any subsequent allocation that reuses this chunk. This is a severe security risk - sensitive data like passwords or keys can persist long after being “freed”.
Experiment 5: Performance Baselines#
Before diving into complex performance analysis (coming in Part 3), I established baselines using our performance analysis tools:
📊 Performance Measurement Tools:
- Timing:
std::time::Instantfor high-resolution timing- Warmup: 1000 allocations to prime the allocator caches
- Statistical method: 100,000 iterations, take median of 5 runs
- CPU isolation: Disabled frequency scaling, pinned to specific cores
- Script:
tools/perf_analysis.shautomates the full benchmark
// perf_analysis.sh dynamically generates performance benchmarking code:
fn benchmark_allocator<F, G>(name: &str, alloc_fn: F, free_fn: G, size: usize)
where
F: Fn(usize) -> *mut c_void,
G: Fn(*mut c_void),
{
const ITERATIONS: usize = 100_000;
// Warmup
for _ in 0..1000 {
let ptr = alloc_fn(size);
if !ptr.is_null() {
free_fn(ptr);
}
}
// Actual benchmark
let start = Instant::now();
let mut pointers = Vec::with_capacity(iterations);
for _ in 0..iterations {
unsafe {
let ptr = libc::malloc(size);
pointers.push(ptr);
}
}
let alloc_time = start.elapsed();
let alloc_rate = iterations as f64 / alloc_time.as_secs_f64();
let start = Instant::now();
for ptr in pointers {
unsafe {
libc::free(ptr);
}
}
let free_time = start.elapsed();
let free_rate = iterations as f64 / free_time.as_secs_f64();
println!("Size {:5}: {:7.1}M allocs/sec, {:7.1}M frees/sec",
size, alloc_rate / 1_000_000.0, free_rate / 1_000_000.0);
}
}To reproduce these measurements:
cd rust-ffi
cargo build --release --bin perf_test
export LD_LIBRARY_PATH=../c-lib:$LD_LIBRARY_PATH
./target/release/perf_testInitial results from our testing:
Size 16: 17.1M allocs/sec, 32.3M frees/sec (58.3ns alloc, 31.0ns free)
Size 64: 12.8M allocs/sec, 31.9M frees/sec (78.0ns alloc, 31.3ns free)
Size 256: 5.6M allocs/sec, 9.3M frees/sec (177ns alloc, 107ns free)
Size 1024: 2.0M allocs/sec, 5.3M frees/sec (490ns alloc, 188ns free)
Size 4096: 0.5M allocs/sec, 2.3M frees/sec (1.9μs alloc, 428ns free)Key observations:
- Small allocations are incredibly fast due to thread-local caching (tcache)
- Free is consistently 2-6x faster than allocation
- Performance degrades with size due to cache misses and syscalls for large allocations
What is tcache? Thread-local cache (tcache) is glibc’s optimization that gives each thread its own small cache of recently freed chunks. This avoids lock contention and makes small allocations extremely fast - no need to access the global heap. Chunks up to 1032 bytes (64 chunks × 7 size classes) can be cached per thread.
- But beware: these are best-case numbers with perfect cache conditions!
Key Takeaways and What’s Next#
This first part of our journey revealed several critical insights:
💡 Key Insights from Our Experiments
Exit Code 0 is the enemy - Our tests showed that mixing allocators often doesn’t crash immediately (exit code 0), creating silent corruption that’s far more dangerous than an immediate segfault
Metadata tells the story - That
0x51value revealed glibc stores size (0x50) + flags (0x1) before each allocation. Different allocators expect metadata at different offsets, causing the mixing failuresMemory overhead is shocking - A 1-byte allocation consumes 24 bytes (2300% overhead!). Understanding size classes is crucial for efficient memory use
Data persists after free - 75% of freed memory remains intact, creating serious security risks. Only the first 16 bytes get overwritten with free list pointers
Cache effects dominate performance - False sharing caused an 8.67x slowdown in our tests. Memory layout matters as much as algorithm choice
Every allocator combination fails differently - Our matrix showed debug allocators catch errors fastest (SIGABRT), while arena allocators silently leak memory
Going back to the interview question: “What happens if you allocate with malloc and free with Rust?”
Now we know: You’ll get exit code 0 (the dangerous silent corruption), followed by unpredictable crashes later. The only safe answer is “never do this.”
In Part 2, we’ll dive deeper with core dump analysis, explore how attackers exploit these vulnerabilities, and see what actually happens at the moment of crash. We’ll use gdb to trace through the exact instruction where things go wrong.
🔍 Preview of Debugging Tools in Part 2:
- Core dumps:
ulimit -c unlimitedand analyzing withgdb- Memory inspection:
x/32gx $rspto examine stack contents- Backtrace analysis:
bt fullto see the exact crash location- LD_PRELOAD hooks: Intercept malloc/free to trace allocations
Stay tuned for Part 2, where things get really interesting - we’ll trigger crashes on purpose, analyze core dumps, and see what actually happens when allocators collide. Spoiler: it’s even messier than you might think.
📝 Repository & Testing Environment
All code from this series is available at https://github.com/notashes/rust-c-memory-interop ↗.
Tests were conducted on:
- Linux 6.5
- glibc 2.39
- Rust 1.75
- Intel Core i7
Your crashes may vary, but the principles remain constant.
Debugging Tips: When Things Go Wrong#
When working with FFI and memory allocators, here are essential debugging techniques:
1. Enable Address Sanitizer (ASan):
# For C code
gcc -fsanitize=address -g your_code.c
# For Rust (in Cargo.toml)
[profile.dev]
opt-level = 0
debug = true2. Use Valgrind for memory leak detection:
valgrind --leak-check=full --show-leak-kinds=all ./your_program3. Core dump analysis:
# Enable core dumps
ulimit -c unlimited
# After crash, analyze with gdb
gdb ./your_program core
(gdb) bt full # Full backtrace
(gdb) info registers
(gdb) x/32xg $rsp # Examine stack4. Common FFI pitfalls to watch for:
- Ownership confusion: Document who owns each pointer
- Lifetime mismatches: Rust may drop memory C still references
- ABI mismatches: Ensure calling conventions match
- Null checks: C functions may return NULL, Rust expects Option
5. Red flags in crash output:
free(): invalid pointer- Wrong allocator or corrupted metadatadouble free or corruption- Classic use-after-freemalloc(): memory corruption- Heap metadata damaged- Exit code 0 with corruption - The worst case, silent failure
How to Reproduce These Experiments#
Want to see these crashes yourself? Here’s how to run the key experiments:
# Clone the repository
git clone https://github.com/notashes/rust-c-memory-interop
cd rust-c-memory-interop
# Build the C library
cd c-lib
make
# Build Rust binaries
cd ../rust-ffi
cargo build --release
# Run crash tests (safely in subprocesses)
cd ..
./tools/run_crash_tests.sh
# Run dynamic analysis tools
./tools/deep_analysis.sh # Generates and runs memory analysis
./tools/perf_analysis.sh # Generates and runs performance benchmarks
# View results
cat test_results/crash_test_results_detailed.txtKey Tools You’ll Need:
gccandmakefor C librarycargofor Rustperffor performance analysis (optional)gdbfor debugging crashes (optional)- Linux system (for glibc-specific features)